
Segment Anything : le premier modèle de segmentation d'image généralisé
Meta veut faciliter l'identification de n'importe quel pixel dans une image

Hello les loopers ! C’est parti pour une nouvelle édition de vos news sur la data science.
Focus on : Segment Anything
La segmentation, qui consiste à identifier à quel objet chaque pixel appartient, est une tâche importante de la Computer Vision et est utilisée pour de nombreuses tâches. Elle permet d’analyser l’imagerie scientifique, servir au guidage des voitures autonomes ou encore éditer ses photos de vacances (et supprimer les touristes gênants).
Créer un modèle de segmentation spécifique à une tâche particulière requiert souvent un expert avec une bonne connaissance du domaine, une puissance de calcul importante et un large dataset d’images annotée. Meta veut résoudre ce problème grâce au projet Segment Anything : une tâche, un dataset et un modèle pour la segmentation d’images.
SAM (Segment Anything Model) a appris une représentation générale de chaque objet, et peut ainsi créer des masques pour n’importe quel objet de n’importe quelle image ou vidéo, et cela même pour des objets non rencontrés lors de son entraînement. Il peut être utilisé dans des domaines très spécifiques sans avoir besoin de ré-entrainement (communément appelé Zero-shot Transfer).
Les différents types de segmentation
Les méthodes de segmentation se divisent en 2 grandes familles, suivant la quantité et le type d’information qui doit être extrait.
Segmentation par instance
La segmentation par instance fonctionne par la détection et la segmentation de chaque objet dans l’image. Ce but est la détection d’objet mais avec la tâche supplémentaire de délimiter l’objet. L’algorithme n’a aucune idée de la zone de l’image dans laquelle se trouve l’objet. Ce modèle est très pratique pour identifier et traquer un objet dans une image.
Segmentation sémantique
La segmentation sémantique demande de labéliser chaque pixel de l’image dans la classe correspondante sans autre information ni contexte. Ce modèle s’avère utile par exemple pour les voitures autonomes qui nécessitent d’affecter une classe à chaque élément sur la route.
Chaque type de segmentation a ses avantages et ses inconvénients. Il convient donc de choisir suivant l’application souhaitée.
Les techniques de segmentation

Techniques traditionnelles
Les techniques traditionnelles de segmentation d’image sont utilisées depuis plusieurs dizaines d’années pour extraire des informations importantes des images. Ce sont des méthodes basées sur des modèles mathématiques et des algorithmes, qui sont ainsi peu coûteuses en puissance de calcul et rapides. On peut distinguer :
Thresholding (seuil) : les pixels sont divisés en classe suivant l’intensité de l’histogramme et suivant des seuils prédéfinis. Des méthodes avec des seuils dynamiques existent.
Region based segmentation (segmentation par zone) : l’image est divisée en régions basées sur des critères de similarité comme la couleur, la texture ou l’intensité.
Edge-based segmentation (segmentation par arêtes) : les arêtes sont identifiées et séparées du fond de l’image. Pour cela, les changements importants d’intensité sont détectés.
Clustering (regroupement) : les pixels avec les mêmes caractéristiques sont regroupés dans des clusters ou segments. Il existe la méthode de K-means clustering (le nombre de clusters est choisi par l’utilisateur) et la méthode du mean-shift clustering (rassembler les pixels dans un maximum de densité local).
Techniques de Deep Learning
Récemment, grâce à la puissance de calcul des réseaux de neurones, de nouvelles méthodes de segmentation d’image ont vu le jour. Pour cela, les modèles de Deep Learning sont entraînés pour détecter quels sont les éléments importants dans une image. L’architecture la plus commune pour la segmentation d’image est la structure d’encodeur-décodeur.
![Autoencoders in Deep Learning: Tutorial & Use Cases [2023]](https://substackcdn.com/image/fetch/$s_!a7Tz!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F4bc3f129-d8ec-4429-8a5e-9b5ea56db1de_1240x752.png "Autoencoders in Deep Learning: Tutorial & Use Cases [2023]")
L’encodeur extrait des informations de l’image grâce aux différents filtres de plus en plus profonds et étroits. En utilisant des modèles déjà pré-entrainés, cela permet d’utiliser ce savoir lors de la segmentation. Le décodeur va ensuite utiliser cette information pour reconstruire l’image d’origine mais à partir de la segmentation trouvée par l’encodeur.
De nombreux modèles de Deep Learning avec de bonnes performances existent :
Foundation models
Une nouvelle sorte de modèles de Deep Learning pour la segmentation voit le jour, ce sont les Foundation models. Ils découpent une image en différentes régions. Ils sont basés sur une architecture CNN, contrairement aux autres modèles de Deep Learning. SAM de Meta en est le premier et principal représentant. De plus, il permet de faire de la segmentation automatique et manuelle.
Fonctionnement de SAM
Pour faire un parallèle avec le domaine du langage naturelle, les modèles à la mode sont les foundation models qui peuvent obtenir de bonnes performances sans, ou avec très peu, de ré-entrainement. C’est l’idée derrière SAM.
SAM peut retourner un mask de segmentation valide pour tout type d’entrée, que ce soit un point dans l’image qui puisse désigner un t-shirt ou la personne qui porte ce t-shirt, un rectangle de sélection ou du texte.

Le modèle est tout d’abord basé sur un premier encodeur d’image, un MAE pre-trained Vision Transformer (ViT) qui a été adapté pour traiter des images haute résolution. Un embedding de l’image est alors réalisé.
Dans le même temps, un petit encodeur transforme toute entrée (point, rectangle ou texte) en un vecteur d’embedding en temps réel. Ces deux informations sont alors combinées, avec des convolutions sur les masks et additionnées, élément par élément.
Le décodeur de mask combine alors l’embedding de l’image, du prompt ainsi que le token de sortie pour prédire le mask de segmentation. Il est basé sur une architecture de décodeur avec des blocks de self-attention et de cross-attention dans les deux directions, ce qui met à jour tous les embeddings.
Le prompt en entrée peut parfois être ambigu et renvoyer à plusieurs éléments : en utilisant la sélection par point, cliquer sur un sac peut désigner le sac à dos, la personne portant le sac à dos ou un élément précis de ce sac à dos. Pour cela, le modèle prédit plusieurs masks pour une seule entrée. La plupart des cas peuvent être résolus avec 3 sélections : le tout, une partie ou une sous-partie. Pour classer ces outputs, le modèle prédit un score de confidence (IoU) pour chaque mask.
La création de SA-1B
Le dataset SA-1B a été créé car le besoin d’un dataset avec une banque d’image conséquente et variée se faisait sentir. SAM a été utilisé pour annoter les images et ensuite ces mêmes images ont permis l’apprentissage de SAM. Ce processus a été utilisé à plusieurs reprises pour améliorer le dataset et le modèle en même temps.
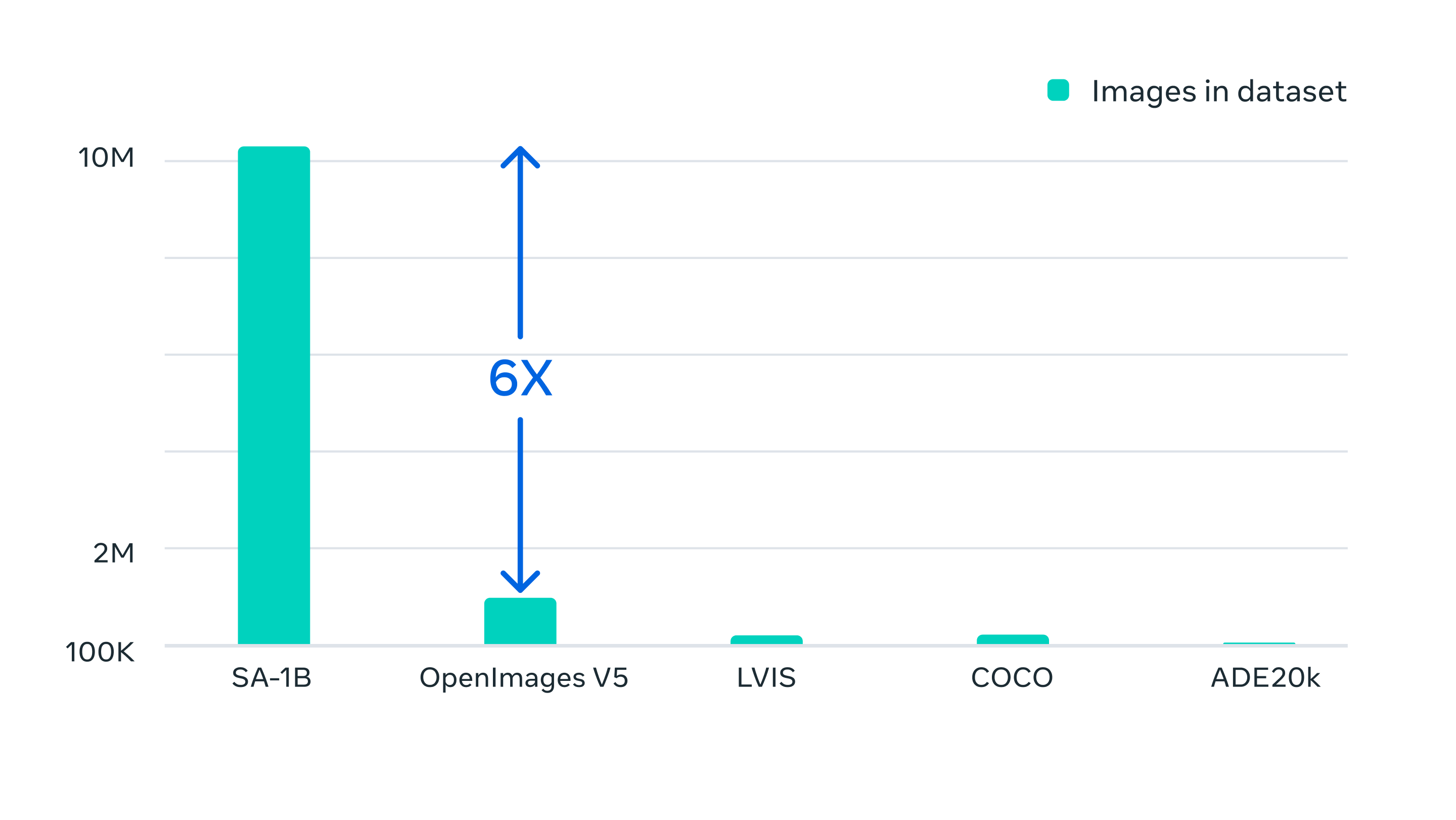
Le dataset final inclut plus de 11 millions d’images provenant de plusieurs endroits géographiques et plus de 1,1 milliards de masks.

Les utilisations possibles


Les possibilités d’utilisation sont nombreuses. SAM pourrait très bien être incorporé dans des lunettes de réalité augmentée et ainsi bien mettre en surbrillance des objets précis pour l’utilisateur. Il pourrait également permettre de détecter des animaux et les suivre au quotidien ou identifier des éléments précis pour la recherche.
Cela semble prometteur et nous avons hâte de voir quelles en seront les utilisations faites !
Sources
https://ai.meta.com/blog/segment-anything-foundation-model-image-segmentation/
https://encord.com/blog/image-segmentation-for-computer-vision-best-practice-guide/
https://arxiv.org/abs/2304.02643
Articles & tutos
Python sur Excel

La nouvelle est tombée il y a quelques jours : Python sera disponible sur Excel ! Vous pourrez faire des graphiques plus complexes en utilisant vos librairies préférées. Alors, qu’en pensez-vous ? Allez-vous l’utiliser ?
Source
https://techcommunity.microsoft.com/t5/excel-blog/announcing-python-in-excel-combining-the-power-of-python-and-the/ba-p/3893439
Confidence, la plateforme d’expérimentation de Spotify

Spotify, le géant du streaming musical, lance sa plateforme d’expérimentation Confidence. L’objectif est de faciliter la mise en place, la coordination, le lancement et l’analyse des tests effectués sur les clients, en utilisant des A/B tests ou des méthodes plus complexes. Cela permet ainsi aux entreprises de tester des nouvelles idées rapidement et les valider au plus vite pour avoir les impacts voulus.
Source
https://engineering.atspotify.com/2023/08/coming-soon-confidence-an-experimentation-platform-from-spotify/
DS / ML book club
Cette communauté de lecteurs lit chaque mois un livre en rapport avec la data science ou le Machine Learning pour ensuite en discuter sur Discord et si possible également avec l’auteur. On peut également trouver une douzaine de vidéos youtube des échanges passés avec les auteurs de livres. N’hésitez pas à aller jeter un oeil, et pourquoi pas participer à cette communauté !
Source
https://dsbookclub.github.io/