


Kedro : un framework pour la data science
Rendre vos projets de data science prêts pour la mise en production

Hello les loopers ! C’est parti pour une nouvelle édition de vos news sur la data science. N’hésitez pas à interagir, partager, cela nous motive énormément.
Sans plus attendre, découvrons le sujet focus !
Focus on : Kedro

Kedro est un package python développé par QuantumBlack à l’origine et actuellement incubé par la Linux Fondation AI & Data. Il aide à développer des pipelines data et machine learning de manière simple, écrire du code propre et passer moins de temps sur le travail de réalisation de pipelines.
Pourquoi utiliser Kedro en tant que data scientist ?
En tant que data scientist, Kedro offre de nombreux atouts :
Ecrire du code propre. L’architecture initiée par Kedro lors de la création d’un projet permet d’utiliser les meilleures pratiques de software engineering.
Permet une transition fluide entre le développement et la production.
Permet de rester à jour sur les méthodes de MLOps. Le code créé à l’aide de Kedro est un code robuste et durable.
Compatibles avec tous les outils de data science. Kedro est compatible avec tous les packages, modèles et outils utilisés en data science.
Création d’un projet de data science
Pour créer votre projet, il suffit de lancer la commande Kedro suivante :
$ kedro new
Architecture cookiecutter
Un projet reprenant l’architecture de cookiecutter datascience est alors créé.

Cette architecture standardisée permet une lecture plus simple du code tout en gardant une certaine adaptabilité. Au delà de Kedro, c’est une architecture que nous vous conseillons d’utiliser car elle est partagée par de nombreuses personnes dans le milieu. N’importe qui qui découvre votre code sait immédiatement où aller chercher les informations.
Catalogue
Kedro dispose également d’un système de catalogue qui permet de définir les différentes bases de données et les sauvegarder. Plein de formats différents sont disponibles : les types habituels comme Pandas, Spark, mais également les types propriétaires aux systèmes de cloud comme S3, GCP, Azure, DBFS, etc.

Pipelines
Kedro fonctionne sur le principe de pipelines. Chaque pipeline est composée de différentes étapes qui sont des nodes. On peut ainsi définir toutes les étapes par lesquelles nos bases de données et autres variables vont passer.
On peut penser à une pipeline de preprocessing avec une étape pour créer des nouvelles variables, une étape pour remplir les valeurs manquantes puis une étape d’encoding de variables catégorielles. On peut ensuite créer une pipeline de modélisation.
L’objectif est ainsi de pouvoir créer des blocs de code qui peuvent ensuite être exécutés chacun indépendamment ou tous ensemble.
Visualiser son code
Flowchart
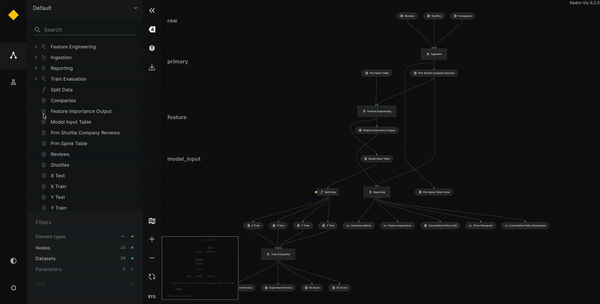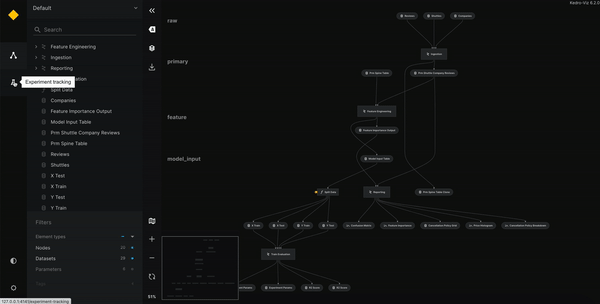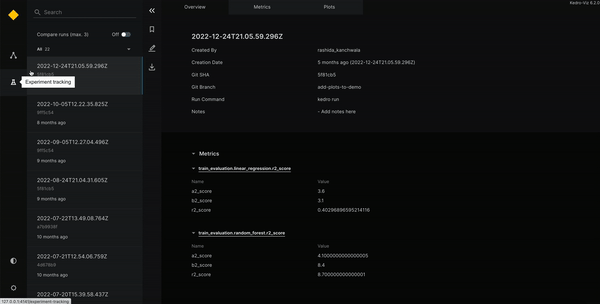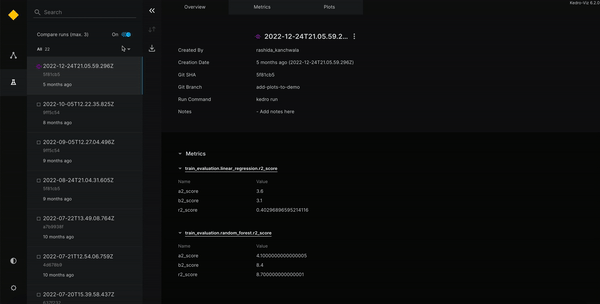
Kedro dispose également d’un package de visualisation. En écrivant le code sous forme de pipelines et de nodes, il est alors possible de voir quelles sont les données utilisées et à quel moment, visualiser les différentes étapes ainsi que regarder le code si besoin.

Vous pouvez directement aller voir un exemple d’utilisation ici.
Experiment tracking
Kedro dispose également d’un système d’experiment tracking lui permettant de garder en mémoire tous les tests des modèles. Un système est directement disponible dans Kedro (sans modèle registry) mais il est également compatible avec MLflow et Neptune.
Pour en connaître plus sur MLflow, nous avons écris une newsletter dessus. Vous pouvez la retrouver ici :
MLflow : tracker vos tests de machine learning

Merci de lire TheLearningLoop’s Substack ! Abonnez-vous gratuitement pour recevoir de nouveaux posts et soutenir mon travail. Hello les loopers ! C’est parti pour une nouvelle édition de vos news sur la data science. On va reprendre des publications régulières. N’hésitez pas à interagir, partager, cela nous motive énormément.
En conclusion
Kedro est donc un framework qui permet de faciliter l’universalité et la robustesse d’un projet de data science, ainsi que sa mise en production. Il demande un petit temps d’adaptation la première fois pour bien comprendre son fonctionnement et comment adapter au mieux son projet. Cependant, le code est beaucoup plus clair et facile à expliquer à un collègue.
Il n’est pas utile de l’utiliser pour un petit projet qui utilise peu de données, avec peu de preprocessing. Cependant, dès qu’il s’agit d’un projet important, utilisant beaucoup de sources de données différentes avec une multitudes d’étapes et de preprocessing différents, Kedro montre alors tout son potentiel.
On vous conseille vraiment de le tester sur un projet que vous avez déjà fait pour comprendre son fonctionnement avant de pouvoir l’appliquer dans un nouveau projet.
Sources
https://kedro.org
https://docs.kedro.org/en/stable/
https://neptune.ai/blog/data-science-pipelines-with-kedro
Articles et tutos
Aura : rendre votre text-to-speech humain

Le nouveau modèle IA Aura de Deepgram permet de lire un texte avec une voix qui est très proche d’une voix humaine. Le ton, le rythme sont très proches de ce que peut avoir une voix humaine. On peut entendre parfois un peu d’émotion. De plus, le modèle est très efficace, avec une latence de seulement 250ms. En prêtant attention, on remarque que ce n’est pas une voix humaine mais c’est déjà très prometteur.
Seriez-vous prêt à prendre rendez-vous par téléphone directement avec une IA ?
Source
https://deepgram.com
SIMA : des agents intelligents qui évoluent dans différents mondes 3D
![url_upload_660f944d58e95.mp4 [video-to-gif output image]](https://substackcdn.com/image/fetch/$s_!qIOC!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F3f098dee-eda1-4bf7-9dc8-bc660fa906f1_600x338.gif "url_upload_660f944d58e95.mp4 [video-to-gif output image]")
DeepMind et l’université de British Columbia ont annoncé la création d’un agent intelligent capable d’évoluer dans différents mondes 3D. Nommés, SIMA (Scalable Instructable Multiworld Agent), cet agent est capable d’évoluer et d’interagir dans différents jeux vidéos en 3D tels que No Man’s Sky, Valheim ou encore Satisfactory. Pour fonctionner, cet agent nécessite juste l’image affichée à l’écran ainsi que des instructions en langage naturel. Il pourrait donc, en théorie, interagir avec n’importe quel jeu 3D ! Cela démontre un beau potentiel pour le futur des agents intelligents !
Source
https://deepmind.google/discover/blog/sima-generalist-ai-agent-for-3d-virtual-environments/
Merci de nous avoir lu et à la prochaine pour d’autres news autour du monde de la Data !